Управление обработкой сигналов
Чтобы задать желаемый способ обработки для каждого из сигналов, вы можете использовать функции языка Си signal() стандарта ANSI или sigaction() стандарта POSIX.
Функция sigaction() предоставляет большие возможности по управлению обработкой сигналов.
Вы можете изменить способ обработки сигнала в любой момент времени. Если вы укажете, что сигнал данного типа должен игнорироваться, то все ждущие сигналы такого типа будут немедленно отброшены.
Некоторые специальные замечания касаются процессов, которые ловят сигналы посредством обработчиков сигналов.
Вызов обработчика сигнала аналогичен программному прерыванию. Он выполняется асинхронно по отношению к остальной части процесса. Таким образом, существует вероятность того, что обработчик сигнала будет вызван во время выполнения любой из имеющихся в программе функций (включая библиотечные функции).
Если в вашей программе не предусмотрен возврат из обработчика сигнала, то могут быть использованы функции siglongjmp() либо longjmp() языка Си, однако, функция siglongjmp() предпочтительнее. При использовании функции longjmp() сигнал остается блокированным.
Иногда может возникнуть необходимость временно запретить получение сигнала, не изменяя метод его обработки. QNX предоставляет набор функций, которые позволяют блокировать получение сигналов. Блокированный сигнал остается ожидающим; после разблокирования он будет доставлен вашей программе.
Пока ваша программа выполняет обработчик сигнала для определенного типа сигнала, QNX автоматически блокирует этот сигнал. Это означает, что нет необходимости заботиться о вложенных вызовах обработчика сигнала. Каждый вызов обработчика сигнала - это неделимая операция по отношению к доставке следующих сигналов этого типа. Если ваш процесс выполняет нормальный возврат из обработчика, сигнал автоматически разблокируется.
| Реализация обработчиков сигналов в некоторых UNIX системах отличается тем, что при получении сигналов они не блокируют его, а устанавливают действие по умолчанию. В результате некоторые UNIX приложения вызывают функцию signal() изнутри обработчика сигналов, чтобы подготовить обработчик к следующему вызову. Такой способ имеет два недостатка. Во-первых, если следующий сигнал поступает, когда ваша программа уже выполняет обработчик сигнала, но еще не вызвала функцию signal(), то программа может быть завершена. Во-вторых, если сигнал поступает сразу после вызова функции signal() в обработчике, то возможен рекурсивный вход в обработчик сигнала. QNX поддерживает блокирование сигналов и, таким образом, не страдает ни от одного из этих недостатков. Вам не нужно вызывать функцию signal() изнутри обработчика сигналов. Если вы покидаете обработчик через дальний переход (long jump), вам следует использовать функцию siglongjmp(). |
Существует важное взаимодействие между сигналами и сообщениями. Если ваш процесс SEND-блокирован или RECEIVE-блокирован в момент получения сигнала, и вы предусмотрели обработчик сигнала, происходят следующие действия:
Если процесс был SEND-блокирован в момент получения сигнала, то проблемы не возникает, потому что получатель еще не получил сообщение. Но если процесс был RECEIVE-блокирован, то вы не узнаете, было ли обработано посланное им сообщение и, следовательно, не будете знать, следует ли повторять Send().
Процесс, играющий роль сервера (т.е. получающий сообщения), может запросить, чтобы он получал извещение всякий раз, когда его процесс-клиент получает сигнал, находясь в состоянии REPLY-блокирован. В этом случае клиент становится SIGNAL-блокированным с ожидающим сигналом. Сервер получает специальные сообщения, описывающие тип сигнала. Сервер может затем выбрать один из следующих вариантов:
ИЛИ
Когда сервер отвечает процессу, который был SIGNAL-блокирован, то сигнал выдается непосредственно после возврата из функции Send(), вызванной клиентом (процессом-отправителем).
Приложение в QNX может общаться с процессом на другом компьютере сети точно так же, как если бы оно общалось с другим процессом на том же самом компьютере. Кстати говоря, с точки зрения приложения нет различия между локальным и удаленным ресурсом.
Такая замечательная степень прозрачности становится возможна благодаря виртуальным каналам (от английского virtual circuit, сокращенно VC). VC - это пути, которые Менеджер сети предоставляет для передачи сообщений, прокси и сигналов по сети. VC способствуют эффективному использованию QNX-сети в целом по нескольким причинам:
Процесс-отправитель отвечает за подготовку VC между собой и тем процессом, с которым он хочет установить связь. С этой целью процесс-отправитель обычно вызывает функцию qnx_vc_attach(). Кроме создания VC, эта функция также создает на каждом конце канала виртуальный идентификатор процесса, сокращенно VID. Для каждого из процессов, VID на противоположном конце виртуального канала является идентификатором удаленного процесса, с которым он устанавливает связь. Процессы поддерживают связь друг с другом посредством этих VID.
Например, на следующем рисунке виртуальный канал соединяет PID 1 и PID 2. На узле 20 - где находится PID 1 - VID представляет PID 2. На узле 40 - где находится PID 2 - VID представляет PID 1. И PID 1 и PID 2 могут обращаться к VID на своем узле так же, как к любому другому локальному процессу, посылая сообщения, принимая сообщения, поставляя сигналы, ожидая и т.д. Так, например, PID 1 может послать сообщение VID на своем конце, и этот VID передаст сообщение по сети к VID, представляющему PID 1 на другом конце. Этот VID затем отправит сообщение к PID 2.
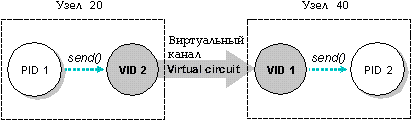
Связь по сети реализуется посредством виртуальных каналов. Когда PID 1 посылает данные VID 2, посланный запрос передается по виртуальному каналу, в результате VID 1 направляет данные PID 2.
Каждый VID поддерживает соединение, которое имеет следующие атрибуты:
Возможно, вам не придется часто иметь дело непосредственно с VC. Так, например, когда приложение хочет получить доступ к ресурсу ввода/вывода на другом узле сети, то VC создается библиотечной функцией open() от имени приложения. Приложение не принимает непосредственного участия в создании или использовании VC. Аналогичным образом, когда приложение определяет местонахождение сервера с помощью функции qnx_name_locate(), то VC автоматически создается от имени приложения. Для приложения VC просто является PID сервера.
Для более подробной информации о функции qnx_name_locate() смотрите описание "Символические имена процессов в главе "Менеджер процессов".
Виртуальное прокси позволяет посылать прокси с удаленного узла, подобно тому, как виртуальный канал позволяет процессу обмениваться сообщениями с удаленным узлом.
В отличие от виртуального канала, который связывает вместе два процесса, виртуальный прокси может быть послан любым процессом на удаленном узле.
Виртуальные прокси создаются функцией qnx_proxy_rem_attach(), которой в качестве аргументов передаются узел (nid_t) и прокси (pid_t).
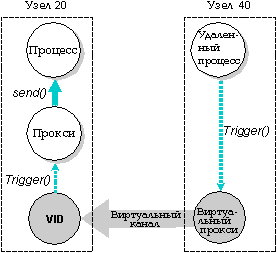
На удаленном узле создается виртуальный прокси, который ссылается на локальный прокси.
Имейте в виду, что на вызывающем узле виртуальный канал создается автоматически посредством функции qnx_proxy_rem_attach().
Отключение виртуальных каналов
Процесс может утратить возможность связи по установленному VC в результате различных причин:
Любая из этих причин может помешать передаче сообщений по VC. Необходимо выявлять такие ситуации с тем, чтобы приложения могли предпринять корректирующие действия, либо корректно завершить свое выполнение. Если это не будет сделано, то ценные ресурсы могут оставаться без необходимости постоянно занятыми.
Менеджер процессов на каждом узле проверяет целостность VC на своем узле. Он делает это следующим образом:
Для установки параметров, связанных с данной проверкой целостности VC, используйте утилиту netpoll.
Другой распространенной формой синхронизации процессов являются семафоры. Операции "сигнализации" (sem_post()) и "ожидания" (sem_wait()) позволяют управлять выполнением процессов, переводя их в состояние ожидания либо выводя из него. Операция сигнализации увеличивает значение семафора на единицу, а операция ожидания уменьшает его на единицу.
При положительном значении семафора, при выполнении операции ожидания, процесс не блокируется. В противном случае операция ожидания блокирует процесс до тех пор, пока какой-либо другой процесс не выполнит операцию сигнализации. Допускается выполнение операции сигнализации один или более раз перед выполнением операции ожидания - это позволит одному или нескольким процессам выполнить операцию ожидания, не блокируясь.
Важное отличие между семафорами и другими примитивами синхронизации заключается в том, что семафоры "асинхронно безопасны" и могут использоваться обработчиками сигналов. Если требуется, чтобы обработчик сигнала выводил процесс из состояния ожидания, то семафоры являются правильным выбором.
Когда принимаются решения по диспетчеризации
Планировщик Микроядра принимает решение по диспетчеризации:
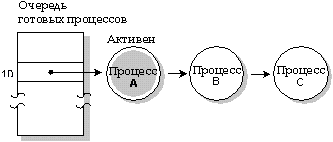
В QNX каждому из процессов присваивается приоритет. Планировщик выбирает для выполнения следующий процесс, находящийся в состоянии READY, в соответствии с его приоритетом. (Программа в состоянии READY - это программа, которая способна использовать ЦП). Для выполнения выбирается процесс с наивысшим приоритетом.
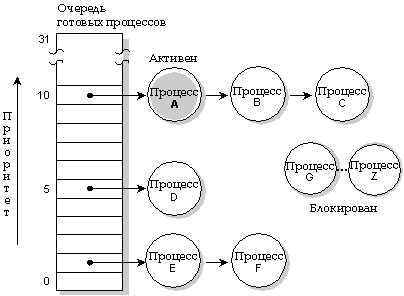
В очереди шесть процессов (A-F), готовых к выполнению и находящихся в состоянии READY. Остальные процессы (G-Z) блокированы. В данный момент выполняется процесс A. Процессы A, B и C имеют наивысший приоритет, поэтому будут разделять центральный процессор в соответствии с алгоритмом диспетчеризации для выполняемого процесса.
Приоритеты, присваиваемые процессам, находятся в диапазоне от 0 (наименьший) до 31 (наивысший). Уровень приоритета по умолчанию для создаваемого процесса наследуется от его родителя; для приложений, запускаемых командным процессором, приоритет обычно равен 10.
| Если вы хотите: | Используйте функцию языка СИ: |
|---|---|
| Определить приоритет процесса | getprio() |
| Установить приоритет для процесса | setprio() |
Чтобы удовлетворить потребность различных приложений, QNX предлагает три метода диспетчеризации:
Каждый процесс в системе может выполняться, используя любой из этих методов. Они действуют применительно к каждому отдельному процессу, а не применительно ко всем процессам на узле.
Помните, что эти методы диспетчеризации применимы, только когда два или более процесса с одинаковым приоритетом находятся в состоянии READY (т.е. эти процессы непосредственно конкурируют друг с другом). Если процесс с более высоким приоритетом переходит в состояние READY, то он немедленно вытесняет все процессы с более низким приоритетом.
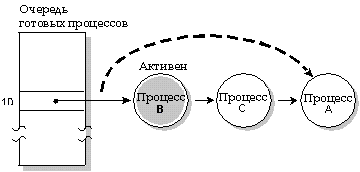
На следующей диаграмме три процесса с одинаковым приоритетом находятся в состоянии READY. Если процесс А блокируется, то выполняется процесс B.
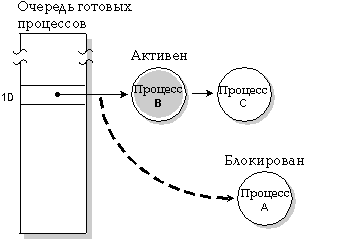
Процесс A блокируется, процесс B выполняется.
Метод диспетчеризации процесса наследуется от его родительского процесса, однако, затем этот метод может быть изменен.
| Если вы хотите: | Используйте функцию языка Си: |
|---|---|
| Определить метод диспетчеризации для процесса | getscheduler() |
| Установить метод диспетчеризации для процесса | setscheduler() |
При FIFO диспетчеризации процесс продолжает выполнение пока не наступит момент, когда он:
FIFO диспетчеризация. Процесс А выполняется до тех пор, пока не блокируется.
Два процесса, которые выполняются с одним и тем же приоритетом, могут использовать метод FIFO для организации взаимоисключающего доступа к разделяемому (т.е. совместно используемому) ресурсу. Ни один из них не будет вытеснен другим во время своего выполнения. Так, например, если они совместно используют сегмент памяти, то каждый из этих двух процессов может обновлять данные в этом сегменте, не прибегая к использованию какого-либо способа синхронизации (например, семафора).
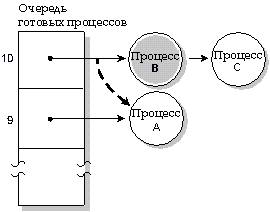
При карусельной диспетчеризации процесс продолжает выполнение, пока не наступит момент, когда он:
Карусельная диспетчеризация. Процесс А выполняется до тех пор, пока он не использовал свой квант времени; затем выполняется следующий процесс, находящийся в состоянии READY (процесс B).
Квант времени - это интервал времени, выделяемый каждому процессу. После того, как процесс использовал свой квант времени, управление передается следующему процессу, который находится в состоянии READY и имеет такой же уровень приоритета. Квант времени равен 50 миллисекундам.
| За исключением квантования времени, карусельная диспетчеризация идентична FIFO-диспетчеризации. |
При адаптивной диспетчеризации процесс ведет себя следующим образом:
Адаптивная диспетчеризация. Процесс А использовал свой квант времени; его приоритет снизился на 1. Выполняется следующий процесс в состоянии READY (процесс B).
Вы можете использовать адаптивную диспетчеризацию в тех случаях, когда процессы, производящие интенсивные вычисления, выполняются в фоновом режиме одновременно с интерактивной работой пользователей. Вы обнаружите, что адаптивная диспетчеризация дает производящим интенсивные вычисления процессам достаточный доступ к ЦП и в то же время сохраняет быстрый интерактивный отклик для других процессов.
Адаптивная диспетчеризация является методом диспетчеризации, использующимся по умолчанию для программ, запускаемых командным интерпретатором.
В QNX обмен данными между процессами в большинстве случаев организован с использованием модели клиент/сервер. Серверы выполняют некоторые сервисные функции, а клиенты, посылая сообщение серверу, запрашивают эти услуги. Как правило, серверы более надежны и жизнеспособны, чем клиенты.
Количество клиентов обычно больше, чем серверов. Как следствие этого, принято запускать сервер с приоритетом более высоким, чем у любого из его клиентов. Может использоваться любой из трех рассмотренных выше методов диспетчеризации, но, наверное, самым распространенным является карусельный.
Если клиент с низким уровнем приоритета посылает сообщение серверу, то его запрос выполняется под более высоким уровнем приоритета, тем, который имеется у сервера. Это косвенным образом повышает приоритет клиента, т.к. именно его запрос заставил сервер выполняться.
Пока для выполнения запроса серверу достаточно короткого промежутка времени, проблем обычно не возникает. Если же выполнение запроса занимает у сервера более продолжительное время, то клиент с низким приоритетом может неблагоприятно повлиять на выполнение других процессов, приоритеты которых выше, чем у клиента, но ниже, чем у сервера.
Чтобы решить эту дилемму, сервер может поставить свой приоритет в зависимость от приоритета того клиента, чей запрос он выполняет. Когда сервер получает сообщение, приоритет будет установлен таким же, как у клиента. Обратите внимание, что изменился только приоритет сервера - его алгоритм диспетчеризации остается неизменным. Если во время выполнения запроса сервер получает другое сообщение, и приоритет нового клиента выше, чем у сервера, то приоритет сервера повышается. Фактически, новый клиент "заряжает" сервер до своего уровня приоритета, позволяя ему закончить выполнение текущего запроса и приступить к обработке запроса нового клиента. Если этого не делать, то фактически приоритет нового клиента понизится, пока он блокирован на сервере с низким приоритетом.
Если вы выбрали клиент-управляемый приоритет для своего сервера, вам следует также запросить доставку сообщений в порядке убывания приоритетов (в противоположность хронологическому).
Чтобы установить клиент-управляемый приоритет, используйте функцию Си qnx_pflags() следующим образом:
qnx_pflags(~0, _PPF_PRIORITY_FLOAT
| _PPF_PRIORITY_REC, 0, 0);
Как бы мы этого не хотели, компьютеры не являются бесконечно быстрыми. Для системы реального времени жизненно важно, чтобы такты работы ЦП не расходовались зря. Также очень важно свести к минимуму время, которое проходит с момента наступления внешнего события до начала выполнения кода программы, ответственной за обработку данного события. Это время называется задержкой.
В QNX системе встречается несколько видов задержек.
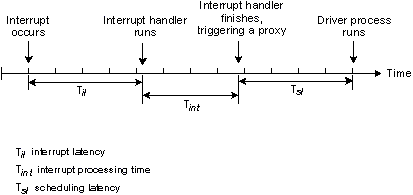
Задержка прерывания - это интервал времени между аппаратным прерыванием и выполнением первой команды программного обработчика прерывания. QNX практически все время оставляет прерывания полностью разрешенными, поэтому задержка прерывания, как правило, не существенна. Однако некоторые критические фрагменты кода требуют, чтобы прерывания были временно запрещены. Максимальная продолжительность такого запрета обычно определяет худший случай задержки прерывания - в QNX это очень небольшая величина.
Следующая диаграмма иллюстрирует случай, когда аппаратное прерывание обрабатывается в установленном обработчиком прерывании. Обработчик прерывания либо просто выполнит команду возврата, либо при возврате запустит прокси.
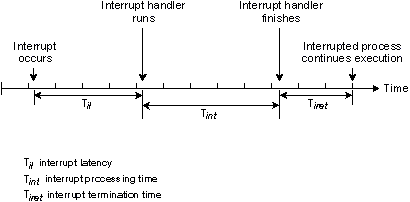
Обработчик прерывания просто завершается.
Задержка прерывания (Til) на приведенной выше диаграмме отражает минимальную задержку - случай, когда прерывания были полностью разрешены в момент, когда произошло прерывание. В худшем случае задержка прерывания составит это время плюс наибольшее время, в течение которого QNX или выполняющийся процесс запрещает прерывания ЦП.
Следующая таблица содержит типичные значения задержки прерывания (TqqqП1ilqqqП0) для разных процессоров:
| Задержка прерывания (Til): | Процессор: |
|---|---|
| 3.3 микросекунды | 166 МГц Pentium |
| 4.4 микросекунды | 100 МГц Pentium |
| 5.6 микросекунды | 100 МГц 486DX4 |
| 22.5 микросекунды | 33 МГц 386EX |
В некоторых случаях обработчик аппаратного прерывания низкого уровня должен передать управление процессу более высокого уровня. В этом случае обработчик прерывания перед выполнением команды "возврат" запускает прокси. Здесь имеет место второй вид задержки - задержка диспетчеризации, - с которой также надо считаться.
Задержка диспетчеризации - это время между завершением работы обработчика прерывания и выполнением первой команды процесса-драйвера. Это время, необходимое для сохранения контекста, выполняющегося в данный момент времени процесса, и восстановления контекста требуемого драйвера. В QNX это время также невелико, хотя и больше задержки прерывания.
Обработчик прерывания завершает работу и запускает прокси.
Важно отметить, что обработка большинства прерываний завершается без запуска прокси. В большинстве случаев обработчик прерывания сам может выполнить все необходимые действия. Запуск прокси, чтобы "разбудить" драйвер, процесс более высокого уровня, происходит только при наступлении важного события. Например, обработчик прерывания для драйвера последовательного порта при каждом прерывании "регистр передачи свободен" будет передавать один байт данных и запустит процесс более высокого уровня (Dev) только тогда, когда выходной буфер, наконец, опустеет.
Следующая таблица содержит типичные значения задержки диспетчеризации (Tsl) для разных процессоров:
| Задержка диспетчеризации (Tsl): | Процессор: |
|---|---|
| 4.7 микросекунды | 166 МГц Pentium |
| 6.7 микросекунды | 100 МГц Pentium |
| 11.1 микросекунды | 100 МГц 486DX4 |
| 74.2 микросекунды | 33 МГц 386EX |
Так как архитектура микрокомпьютеров позволяет назначать приоритеты аппаратным прерываниям, то прерывания с более высоким приоритетом могут вытеснять прерывания с меньшим приоритетом.
Этот механизм полностью поддерживается в QNX. Выше были рассмотрены простейшие - и наиболее типичные - ситуации, когда происходит только одно прерывание. Практически такой же расчет времени справедлив для прерывания с наивысшим приоритетом. При рассмотрении наихудшего случая для прерывания с низким приоритетом необходимо учитывать время обработки всех прерываний более высокого уровня, т.к. в QNX прерывание с более высоким приоритетом вытеснит прерывание с меньшим приоритетом.
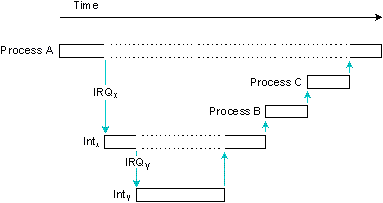
Выполняется процесс A. Прерывание IRQx вызывает выполнение обработчика прерывания Intx, который вытесняется IRQy и его обработчиком Inty. Inty запускает прокси, вызывающее выполнение процесса B, а Intx запускает прокси, вызывающее выполнение процесса C.
Эта глава охватывает следующие темы:
Обязанности Менеджера процессов
Менеджер процессов тесно взаимодействует с Микроядром, чтобы обеспечить услуги, составляющие сущность операционной системы. Хотя он и является единственным процессом, который использует то же адресное пространство, что и Микроядро, Менеджер процессов выполняется как истинный процесс. И он, как и все остальные процессы, подвергается диспетчеризации со стороны Ядра и использует предоставляемые Микроядром примитивы передачи сообщений для связи с другими процессами в системе.
Менеджер процессов отвечает за создание новых процессов в системе и за управление основными ресурсами, связанными с процессом. Все эти услуги предоставляются посредством сообщений. Так, например, если процесс хочет породить новый процесс, он делает это, посылая сообщение с указанием атрибутов создаваемого процесса. Обратите внимание, что т.к. сообщения передаются по сети, вы можете легко создать процесс на другом узле сети, послав сообщение Менеджеру процессов на этом узле.
QNX поддерживают три примитива создания процесса:
Примитивы fork() и exec() определены стандартом POSIX, а примитив spawn() реализован только в QNX.
Примитив fork() создает новый процесс, который является точной копией вызвавшего его процесса. Новый процесс использует тот же самый код, что и породивший его процесс, и наследует копию всех данных родительского процесса.
Примитив exec() заменяет вызвавший процесс новым. После успешного вызова exec() возврата не происходит, т.к. образ вызывающего процесса заменяется образом нового процесса. Обычной практикой в POSIX-системах для создания нового процесса - без удаления вызывающего процесса - является сначала вызов fork(), а затем вызов exec() из порожденного процесса.
Примитив spawn() создает новый процесс как потомок вызывающего процесса. С его помощью можно избежать вызовов fork() и exec(), используя более быстрый и эффективный способ создания новых процессов. В отличие от fork() и exec(), которые по своей природе выполняются на том же самом узле, что и вызывающий процесс, примитив spawn() может создавать процессы на любом узле сети.
Когда с помощью одного из трех рассмотренных выше примитивов задается новый процесс, он наследует многое из своего окружения от родителя. Это сведено в следующую таблицу:
| Наследуемый параметр | fork() | exec() | spawn() |
|---|---|---|---|
| Идентификатор процесса | нет | да | нет |
| Открытые файлы | да | по выбору* | по выбору |
| Блокировка файлов | нет | да | нет |
| Ожидающие сигналы | нет | да | нет |
| Маска сигналов | да | по выбору | по выбору |
| Игнорируемые сигналы | да | по выбору | по выбору |
| Обработчики сигналов | да | нет | нет |
| Переменные окружения | да | по выбору | по выбору |
| Идентификатор сеанса | да | да | по выбору |
| Группа процесса | да | да | по выбору |
| Реальные UID, GID | да | да | да |
| Эффективные UID, GID | да | по выбору | по выбору |
| Текущий рабочий каталог | да | по выбору | по выбору |
| Маска создания файлов | да | да | да |
| Приоритет | да | по выбору | по выбору |
| Алгоритм диспетчеризации | да | по выбору | по выбору |
| Виртуальные каналы | нет | нет | нет |
| Символьные имена | нет | нет | нет |
| таймеры реального времени | нет | нет | нет |
*по выбору: вызывающий процесс может по необходимости выбрать - да или нет.
Процесс проходит через четыре стадии:
Создание нового процесса состоит из присвоения новому процессу идентификатора (ID) процесса и подготовки информации, которая определяет окружение нового процесса. Большая часть этой информации наследуется от родительского процесса (смотри раздел "Наследование").
Загрузка образа процесса производится нитью загрузчика. Код загрузчика находится в Менеджере процессов, но нить выполняется под ID нового процесса. Это позволяет Менеджеру процессов обрабатывать и другие запросы во время загрузки программы.
После того, как код программы загружен, процесс готов к выполнению; он начинает конкурировать с остальными процессами за ресурсы ЦП. Заметьте, что все процессы выполняются параллельно со своими родителями. Кроме того, смерть родительского процесса не означает автоматическую смерть его дочерних процессов.
Процесс завершается одним из двух способов:
Завершение включает две стадии:
Если родительский процесс не вызвал wait() или waitpid(), то дочерний процесс становится "зомби" и не будет завершен, пока родительский процесс не вызовет wait() или не завершит выполнение. (Если вы не хотите, чтобы процесс ждал смерти дочерних процессов, вы должны либо установить _SPAWN_NOZOMBIE флаг функциями qnx_spawn() или qnx_spawn_options(), либо установить действие SIG_IGN для сигнала SIGCHLD посредством функции signal(). Таким образом, дочерние процессы не будут становиться зомби после смерти.)
Родительский процесс может ждать смерти дочернего процесса, запущенного на удаленном узле. Если родитель процесса-зомби умирает, то зомби освобождается.
Если запущена утилита dumper и процесс завершается в результате получения сигнала, то генерируется дамп памяти. Вы можете затем исследовать его с помощью отладчика.
Процесс всегда находится в одном из следующих состояний:
| Для получения более полной информации о блокированном состоянии обратитесь к главе "Микроядро". |
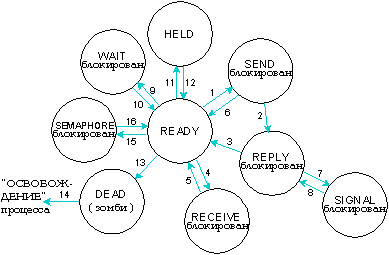
Возможные состояния процесса в QNX.
Показаны следующие переходы:
Определение состояний процесса
Чтобы определить состояние конкретного процесса из командного интерпретатора (Shell), используйте утилиты ps и sin (внутри приложений используйте функцию qnx_psinfo()).
Чтобы определить состояние операционной системы в целом из командного интерпретатора (Shell), используйте утилиту sin (внутри приложений используйте функцию qnx_osinfo()).
Утилита ps определена стандартом POSIX; ее использование в командных файлах может быть переносимым в другие системы. Утилита sin, напротив, уникальна для QNX; она дает вам полезную информацию, специфическую для QNX, которую вы не можете получить, используя утилиту ps.
QNX стимулирует разработку приложений, которые разбиты на несколько взаимодействующих процессов. Такое приложение, которое существует как группа взаимодействующих процессов, имеет большие возможности распараллеливания и может быть распределено по сети для лучшей производительности.
Однако разделение приложений на взаимодействующие процессы требует ряда специальных соображений. Чтобы взаимодействующие процессы могли установить связь между собой, они должны иметь возможность определить идентификаторы друг друга. Например, допустим, что имеется сервер базы данных, который может обслуживать произвольное количество клиентов. Клиенты могут запускаться и прекращать работу в любое время, однако сервер всегда остается доступным. Как процессы-клиенты узнают идентификатор процесса-сервера базы данных с тем, чтобы послать ему сообщение?
В QNX процессы могут присваивать себе символьные имена. В контексте одного узла процесса могут зарегистрировать эти имена у Менеджера процессов на том узле, на котором они выполняются. Остальные процессы могут затем запросить у Менеджера процессов идентификатор процесса, ассоциированный с определенным именем.
Ситуация становится более сложной, если мы рассмотрим сеть, в которой сервер обслуживает клиентов, находящихся на различных узлах. Поэтому в QNX предусмотрена поддержка как глобальных, так и локальных имен. Глобальные имена определены для всей сети, в то время как локальные имена определены только для того узла, на котором они зарегистрированы. Глобальные имена на